People often navigate in an unknown environment by observing the surrounding environment and following instructions. These instructions are mainly composed of landmarks and directions and other common words. Recently, Google has applied human-like instructions to robot navigation tasks in two-dimensional workspaces, provided instructions to agents, and trained them to follow instructions. In order to effectively navigate, Google proposed FollowNet, an end-to-end subtle neural architecture for learning multimodal navigation strategies. Improve the ability of an agent to navigate in the environment.
Understanding and following the instructions provided by humans allows the robot to navigate effectively in an unknown situation. We provide FollowNet, an end-to-end subtle neural architecture for learning multimodal navigation strategies. FollowNet maps natural language instructions and visual depth inputs to locomotion primitives. FollowNet uses an attention mechanism to process instructions when performing navigation tasks, which is conditioned on its visual depth input to focus on the relevant part of the command. Sparse rewards for deep reinforcement learning (DRL) must also learn state representations, attentional functions, and control strategies. We evaluate our agents on a data set of complex natural language instructions to guide the agent through a rich, realistic analog home data set. We point out that the FollowNet Agent learns to execute previously invisible instructions described in similar words and successfully navigates along paths not encountered during training. In the absence of an attention mechanism, the agent showed a 30% improvement compared to the baseline model, and the success rate under the new directive was 52%.
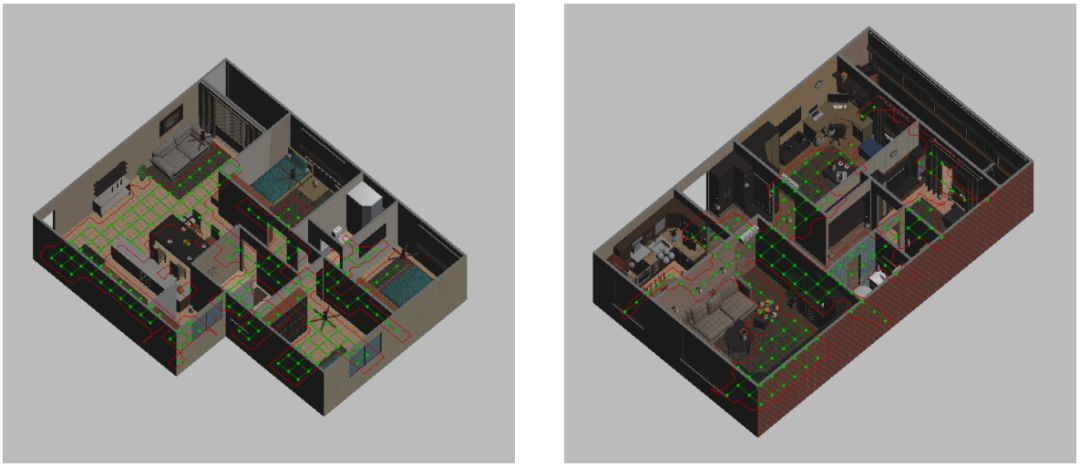
Figure 1: Three-dimensional rendering of a house for navigating from natural language instruction learning.
People often navigate in an unknown environment by observing the surrounding environment and following instructions. These instructions consist primarily of landmarks and directional directives and other commonly used words. For example, people can find a kitchen in a home they haven't visited before by following the instructions: "Turn right at the dining table, then take the second left". This process requires visual observations, such as a table in the field of vision or knowledge about a typical foyer, and perform the action in this direction: Turn left. There are multiple dimensions of complexity here: limited horizons, modifiers like "second", synonyms like "take" and "turn", understanding "take left left" referring to doors, and so on.
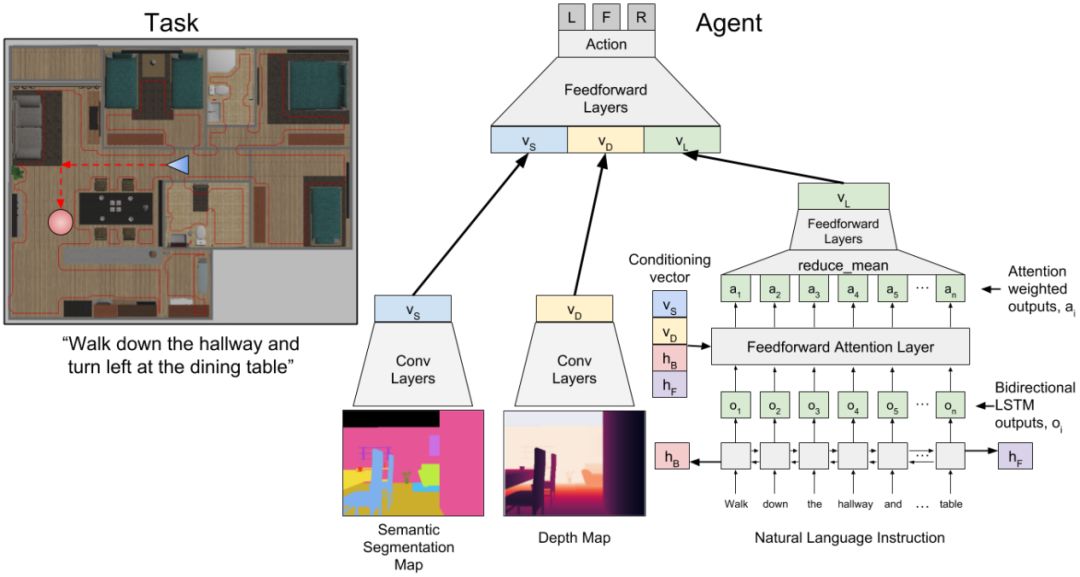
Figure 2: A neural model that maps visual and language input to navigation actions. Left: An example task where the robot starts from the position and direction specified by the blue triangle and must reach the target position specified by the red circle. The robot will receive a natural language instruction to follow the red marked path listed below the image. Right: FollowNet architecture.
In this article, we apply human-like instructional compliance to the navigation of robots in a two-dimensional workspace (Figure 1). We provided robots with example instructions similar to those described above, and trained a Depth Reinforcement Learning (DRL) agent to follow instructions. When starting from a different location, the agent is tested to the extent that it follows the new instructions. We did this through a new deep neural network architecture, FollowNet (Figure 2), which uses Deep Q-Network (DQN) for training. The viewing space consists of natural language instructions and visual depth observations from the vantage point of the robot (Figure 4b). The output of the strategy is the next motion primitive to be executed. The robot moves along an obstacle-free grid, but the instructions require the robot to move beyond a variable number of nodes to reach the destination. The instructions we use (Table I) include implicitly encoded rooms, landmarks, and motion primitives. In the above example, "Kitchen" is the room in the target location. The “table†is an example of a landmark. At this point, the agent may change direction. In the absence of knowledge of the agent, both rooms and landmarks are mapped to clustered grid points. We use sparse rewards, and only give bonuses to agents when they reach a signpost.

Table 1: Samples of instructions used during training.
It can be said that the novelty of the FollowNet architecture lies in a language instruction attention mechanism, which is based on the sensory observation of the agent. This allows the agent to do two things. First, it tracks instruction commands and focuses on different parts while exploring the environment. Second, it associates motion primitives, sensory observations, and various parts of instructions with received rewards, allowing the agent to generalize to new instructions.
We evaluate the degree of generalization of agents in new directives and new athletic programs. First, we assess how well it follows the previously invisible two-step instructions in houses familiar to the agent. The results showed that the agent was able to fully comply with 52% of the instructions, and locality followed 61% of the instructions, an increase of 30% from the baseline. Second, the same instruction is valid for a group of different starting positions. For example, the "leave room" command is valid for any starting position in the room, but the robot's exercise plan that needs to be performed to complete the task may be very different. In order to understand the extent to which the exercise plan is generalized to a new starting position, we evaluate the agent's compliance with an instruction it has already trained in its instructions (up to five steps), but now it is starting from the new starting position. of. The agent can locally complete 70% of the instructions and completely complete 54% of the instructions. From this perspective, multi-step instructions are also challenging for people.
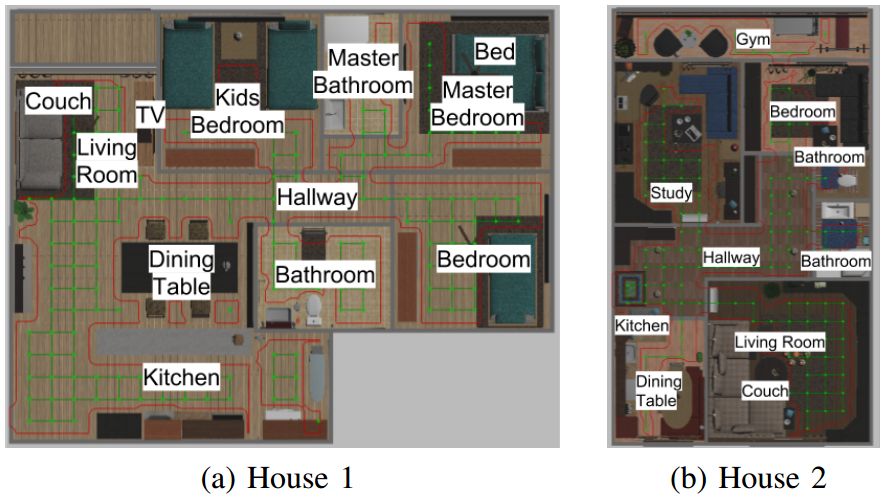
Figure 3: Landmarks and grids in the environment.
End-to-end navigation methods use depth-enhanced learning robots for sensory observations and relative target positions. In this study, we provide natural language instructions rather than explicit goals, so agents must learn to interpret instructions to accomplish their goals. One of the challenges of applying reinforcement learning to robots is the state space representation. The large state space slows down the learning process, so different approximation techniques are often used. These examples include Probabilistic Roadmaps (PRM) and simple spatial discretization. Here, we discretize the two-dimensional workspace and allow agents to move from node to node through the grid. Essentially, we assume that the robot can avoid obstacles by performing motion primitives corresponding to the movements and safely move between two grid points.
Deep learning has achieved great success in learning natural language and vision, even in combining visual and language learning. To be applied to robot motion planning and navigation, language learning usually requires a certain degree of parsing, including formal expressions, semantic analysis, probability map models, coding and alignment, or basic task languages. However, through the natural language learning target mark, it is mainly through learning to translate natural language instructions into a hierarchical structure for robot motion planning and execution and active learning process. Here, similar to the article published by P. Anderson et al. in 2017, our goal is to implicitly learn the labels of landmarks (goals) and movement primitives and their interpretation of visual observations. In contrast, we use DQN on FollowNet to learn navigation strategies. Other studies use the curriculum to accomplish multiple tasks in an environment.
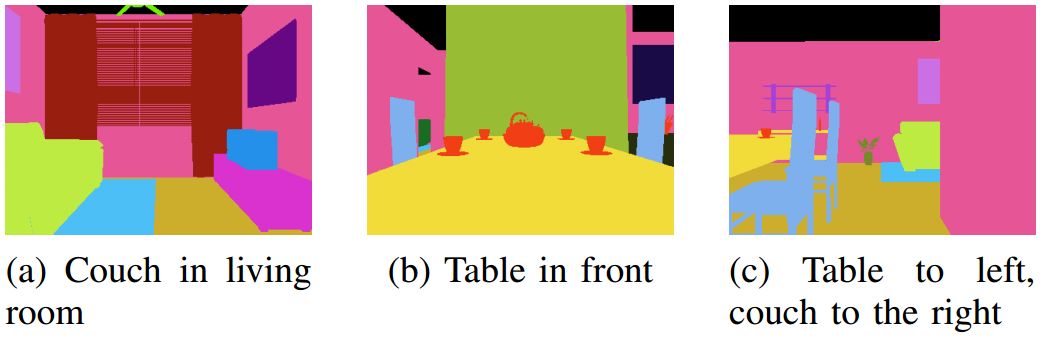
Figure 4: Semantic segmentation of the FollowNet Agent. The color corresponds to the object type (the agent does not know) and is consistent between the house and the vantage point. The sofa is green (a and c) and the dining table is yellow (b and c).
Another research work that combines 3D navigation, visual, and natural language is learning to answer questions. These problems stem from a set of specified questions where some of the keywords are replaced. In our research work, the language instructions provided to the agent were independently created by four individuals and submitted to the agent without any processing. There are several ways to learn from unfiltered language and visual input. In these methods, visual input is an image of the entire planning environment. Instead, FollowNet only receives some environmental observations.
This article describes the FollowNet architecture, which uses attention mechanisms to process natural language instructions based on multi-modal sensory observations as action value function approximators in DQN. The trained model uses only visual and depth information to learn natural language instructions. The results show that we can learn the generalization of directional instructions and sign recognition at the same time. The agent successfully followed the novel two-step directions most of the time (in early childhood), a 30% increase over the baseline level. In the future research work, our goal is to train agents on a larger data set, conduct more in-depth analysis and experience assessment across multiple domains, and explore the generalization ability across different environments.
GW9 outdoor AC high-voltage disconnector is an AC 50H outdoor device, which is used in the power supply network with frequency of 50HZ and 10kV. It is used for the switching of high-voltage lines with voltage and without load, and for the electrical isolation of the overhauled high-voltage bus, circuit breaker and other electrical equipment from the live high-voltage lines. It can also be used to open and close very small capacitive current and inductive current.
GW9 outdoor high-voltage disconnector features:
They are composed of base, post insulator, conductive part and mechanism part. Knife type structure is adopted to open and close the circuit to cut off and close the line. Each phase of the knife is composed of two conductive blades, which are equipped with compression springs on both sides. The contact pressure required for switching the knife can be obtained by adjusting the height of the springs. When the switch is opened and closed, the insulating hook bar operating mechanism can be used for closing movement

Ceramic disconnectors,Ceramic knife switch,high voltage Isolating switch,Epoxy resin isolating switch,high voltage disconnector
Henan New Electric Power Co.,Ltd. , https://www.newelectricpower.com