Editor's note: There are many ways to recognize text in images, but most of them are recognition in the horizontal direction. Once the rotation angle is established, these methods may "fail". Several researchers from Fudan University and the Chinese Academy of Sciences have proposed a framework that can recognize rotated text in images. The following is Lunzhi's compilation of the paper.

Summary
This article introduces a new rotation-based framework that can detect and recognize text in any direction in natural scenes. We propose Rotation Region Proposal Networks (RRPN), which is used to generate a tilted frame with information about the rotation angle of the image. After that, this information will be adapted to the bounding box, so that the text area can be determined more accurately in different directions. The Rotation Region-of-Interest (RRoI) pooling layer maps the candidate window in a random direction to the feature map of the text region classifier.
The entire frame is built based on the structure of the regional candidate frame. Compared with the previous text detection system, it can ensure higher computational efficiency in text detection in random directions. We experimented with this framework in three real-world scenarios and found the efficiency it showed compared to the previous methods.
Background introduction
Text detection is a hot topic in the CV field. Its goal is to locate text areas in a given image. This task is the premise of many complex tasks, such as visual classification, video analysis, and other mobile applications. Although many commercial products have been launched, due to the complexity of the scene, text recognition in natural scenes is still subject to many restrictions, such as uneven light, blurred pictures, distorted angles, and different directions. This article focuses on the substandard text areas in real life.
Some recent studies have proposed detection methods for text with random directions. In general, these methods roughly include two steps: segmentation networks (full convolutional networks) and geometric methods for tilting candidate frames. However, segmentation of images is usually time-consuming, and some systems require multiple post-processing to generate the final text area candidate frame, so it is not as efficient as a direct detection network.
In this paper, we propose a rotation-based method and an end-to-end text detection system that can generate candidate frames in any direction. Compared with the previous method, our main results are:
This time the framework can predict the direction of the text line based on the candidate box area, so that the candidate box can better adapt to the text area. The new elements added to the framework, such as the RRoI pooling layer and rotating candidate frames, are integrated into the framework to ensure efficient computing power.
We also propose a new fine-tuning method for the candidate frame area to improve the performance of text detection in any direction.
We applied the new framework to three scene data sets and found that it was more accurate and efficient than the previous method.
Concrete framework
First, the overall structure of the framework is shown in the figure below:
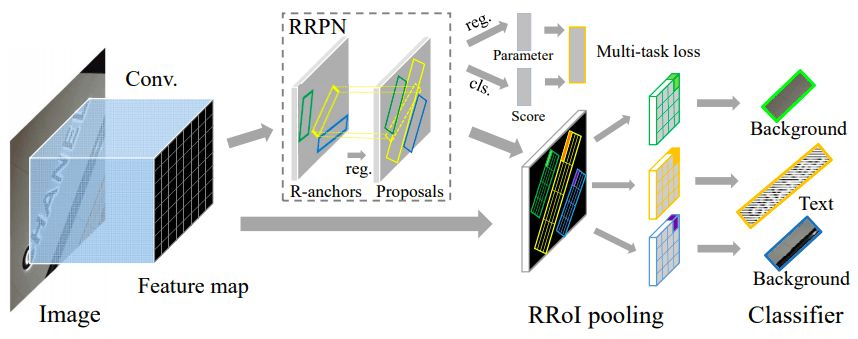
The front part of the frame is the convolutional layer of VGG-16, which consists of two parts: RRPN and a replica of the feature map of the last convolutional layer. RRPN can generate candidate boxes with random directions for text samples, and then perform regression processing on the candidate boxes to better adapt to the text area. The two layers separated from RRPN are classification layer (cls) and regression layer (reg).
The score of cls and the candidate frame information in reg form the output results of the two layers, and their loss will form a multi-task loss function by calculating the total structure. After that, the RRoI pooling layer will play the role of a maximum pooling layer, projecting the text candidate frame in any direction on the RRPN onto the feature map.
Finally, the two fully convolutional layers are combined into a classifier, and the area with RRoI features is divided into text or background.
In the training phase, the real text area uses five tuples to represent the rotated bounding box, namely (x, y, h, w, θ), (x, y) represents the coordinates of the geometric center of the bounding box, h and w They represent the shorter and longer sides of the bounding box, and θ represents the included angle.
Rotating connection points (anchors)
Traditional connection points are represented by scale and aspect ratio parameters, which are usually not effective for text detection in reality. So we designed the R-anchors through adjustment. See the figure below for specific representation:
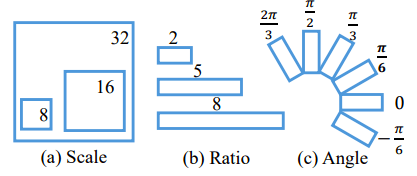
There are six different rotation directions, which are the result of comprehensive consideration of coverage and calculation efficiency. Second, because the text area often has a special shape, the aspect ratio is changed to 1:2, 1:5, and 1:8 to cover wider text.
Learn to rotate the candidate frame
After R-anchors are generated, in order to perform network learning, R-anchors need to be sampled. The loss function of the candidate box forms the multi-task loss, which is defined as:
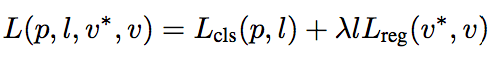
Where l is the indicator of the category label, the parameter p is the category probability calculated by the softmax function, v represents the predicted tuple of the text label, and v* represents the true value.
The following figure shows the comparison between the regressed image and the unregressed image:

(A) is the input image, (b) is the direction and connection point without regression processing, (c) is the processed point
The direction of the white line indicates the direction of the R-anchors, and the length of the white line indicates the feedback of the connection points to the text.
The following figure is a comparison of different multi-task loss values:

Experimental effect
We conducted experiments on three data sets: MSRA-TD500, ICDAR2015 and ICDAR2013. The three data sets are commonly used data sets for text detection. First, we compare the rotated and horizontal candidate boxes:

The results show that the rotation-based method can more accurately determine the text area without too much background, which shows the effectiveness of adding a rotation strategy to the frame. However, although the detection efficiency has been improved, there are still cases of detection failure in MSRA-TD500:

Under unbalanced light (a), very small fonts (b), and long texts (c), the detection will fail
But the final performance on the three data sets is still very good:


10.1 Inch Laptop,win10 Laptops,win11 Laptops
Jingjiang Gisen Technology Co.,Ltd , https://www.jsgisengroup.com