In recent years, the development of deep learning has become more and more rapid, and it has become more and more difficult to keep up with the progress of deep learning. Almost every day there is innovation about deep learning, and most of the deep learning innovations are hidden in research papers published in ArXiv and Spinger.
For the sake of brevity, this article only introduces the more successful deep learning architecture in the field of computer vision.
table of Contents
What is the "Advanced Architecture" for deep learning?
Different types of computer vision tasks
Various deep learning architectures
What is the "Advanced Architecture" for deep learning?
Compared to a simple machine learning algorithm, the deep learning algorithm contains a more diverse model. The reason for this is that neural networks have great flexibility when building a complete model.
Sometimes, we can also compare neural networks to Lego bricks, which can be used to build any simple or complex small building.
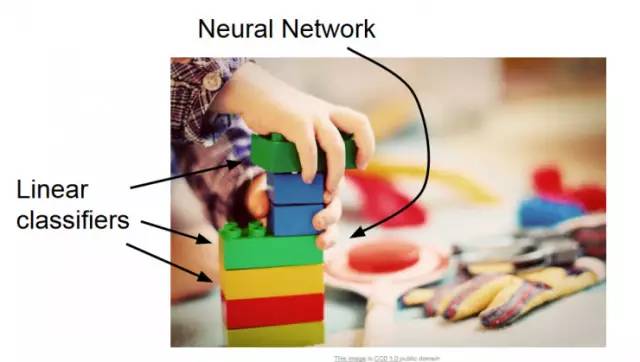
We can actually define the "high-level architecture" as a deep learning architecture with a successful model record. Such "high-level architecture" mainly appears in the challenges similar to ImageNet. In these challenges, your task is to solve the problem, such as Image recognition is done with the given data. In a nutshell, ImageNet is a data set challenge, and the data set is obtained from ILSVR (ImageNet Mass Visual Recognition).
Like the architecture that will be mentioned below, each of these architectures has subtle differences between them, and it is these differences that distinguish them from ordinary models, allowing them to take advantage of common models when solving problems. . These architectures are also part of the "depth model", so their performance is likely to be better than their corresponding "shallow model."
Different types of "computer vision tasks"
This article focuses on "computer vision," so it naturally involves the task of "computer vision." As the name implies, the "computer vision task" is to build a computer model that can replicate the tasks of human vision. This essentially means that what we see and perceive as vision is a program that can be understood and completed in an artificial system.
The main types of computer vision tasks are:
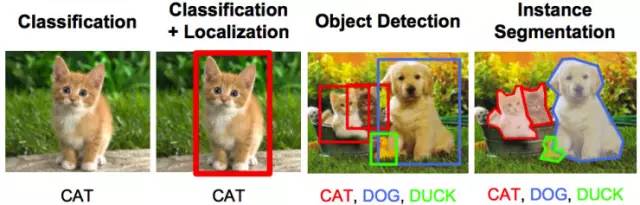
Object Recognition/Classification: In object recognition, you get an original image, and your task is to determine which category the image belongs to.
Classification and positioning: If there is only one object in the image, then your task is to find the location of the object. This issue should be more specifically expressed as a "positioning problem."
Object Detection: In object detection, your task is to identify where the object is in the image. These objects may belong to the same category or to different categories.
Image Segmentation: Image segmentation is a slightly more complex task whose purpose is to map individual pixels of an image to their respective categories.
Currently, we have learned about the "Advanced Architecture" for deep learning and explored various types of computer vision tasks. So next, we will list the most important deep learning architectures and give a brief introduction to these architectures:
1
AlexNet
AlexNet is the first deep learning architecture that was developed and introduced by Geoffrey Hinton, one of the pioneers of deep learning, and his colleagues. AlexNet is a seemingly simple but very powerful network architecture that paves the way for breakthrough research in deep learning today. The picture below is the AlexNet architecture:
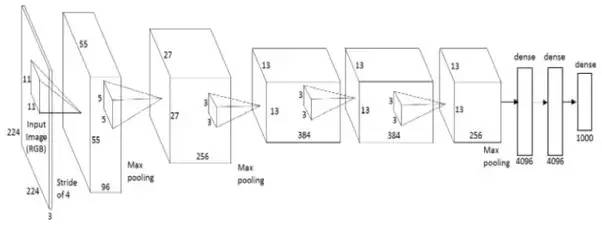
As you can see from the exploded view, AlexNet is actually a simple architecture in which the convolutional layer and the accumulation layer are superimposed on each other, and the topmost layer is the fully connected layer.
As early as the 1980s, the AlexNet model was conceptualized. The key to distinguishing AlexNet from other models is its mission size and the scale of the GPU it uses for training. In the 1980s, the CPU used to train neural networks. AlexNet took the lead in using the GPU, which increased the training speed by about ten times.
Although AlexNet is now somewhat outdated, it is still the starting point for using neural networks to accomplish a variety of tasks. Whether you are completing a computer vision task or a voice recognition task, you still need AlexNet.
2
VGG Net
"VGG Net" was introduced by researchers at the "Visual Image Research Group" at the University of Oxford. The biggest feature of the VGG network is its pyramid shape, which is relatively wide near the bottom of the image, while the top layer is relatively narrow and deep.
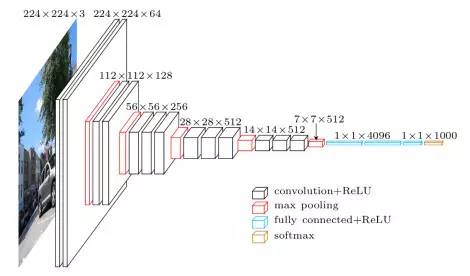
As shown, VGG Net contains a continuous convolutional layer followed by an accumulation layer. The accumulation layer is responsible for making the layers narrower. In this paper, which was jointly completed by the researchers in the group, they proposed various types of networks. The main difference between these network architectures is the depth.
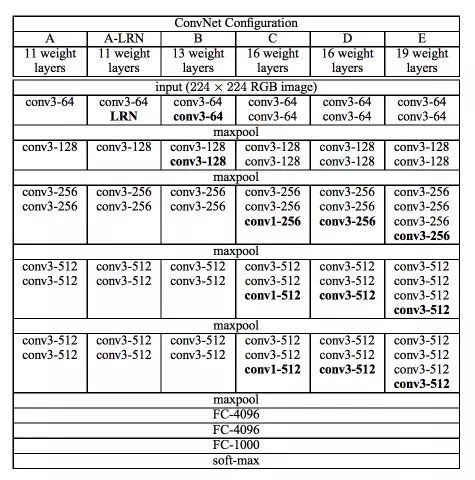
The advantages of the VGG network are:
1. This is a very effective network architecture for benchmarking a specific task.
102. At the same time, there are a large number of free VGG pre-training networks on the Internet, so VGG is often used in a variety of applications.
On the other hand, the main drawback of VGG is that if you train from scratch, the training speed will be very slow. Even with a pretty good GPU, it still takes more than a week to get up and running.
3
GoogleNet
GoogleNet (also known as "InceptionNet") is a network architecture designed by Google researchers. GoogleNet won the 2014 ImageNet contest, proving it to be a powerful model.
In this network architecture, researchers have not only deepened the depth of the network (GoogleNet contains 22 layers, but VGG network has only 19 layers), and also developed a new method called "Inception Module".
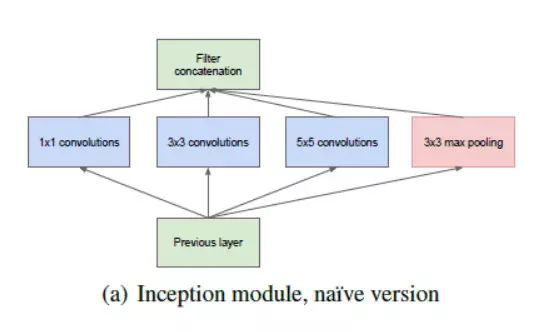
As shown in the figure above, this architecture has changed dramatically from the orderly architecture we saw earlier. A variety of "feature extractors" have appeared in a single layer. This indirectly improves the performance of the network, because when dealing with tasks, the network has a wide choice in the self-training process. It can either select the convolution input or choose to accumulate the input directly.
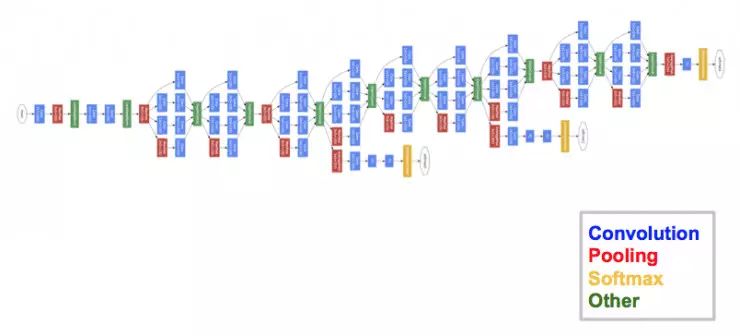
The final architecture consists of a number of Inception modules stacked on top of each other. Most of the top layers have their own output layers, so GoogleNet's training is slightly different from other models. But these differences can help the model complete the convolution faster, because these layers not only have common training, but also independent training.
The advantages of GoogleNet are:
1. GoogleNet training speed is faster than VGGNet.
2. Pre-trained GoogleNet is smaller than the pre-trained VGG network. A VGG model can take up more than 500MB, while GoogleNet only accounts for 96MB.
So far, GoogleNet has no direct flaws, but the article proposes some changes that will help GoogleNet further improve. One of the changes is called "XceptionNet", in which the divergence limit of the "initial module" is increased. In theory, its divergence can now be infinite.
4
ResNet
ResNet is a network architecture that truly defines the depth of deep learning architecture. The "residual network", also known as ResNet, contains many consecutive "residual modules" that form the basis of the ResNet architecture. The “residual module†is shown below:
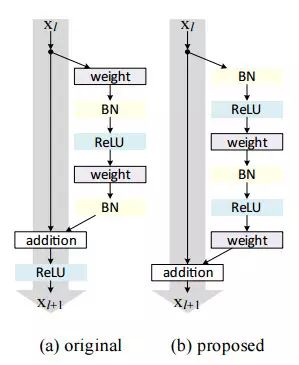
In simple terms, a "residual module" has two choices - it can choose to execute a set of functions on the input, or you can choose to skip these steps.
Similar to GoogleNet, these "residual modules" are superimposed on each other to form a complete network.

Some of the new technologies introduced by ResNet are:
1. Use standard SGD instead of fancy "adaptive learning" techniques. This is done through an initialization function that maintains normal training.
2. Change the way the input is pre-processed, first batch the input, and then input to the network.
The main advantage of ResNet is that thousands of residual layers can be used to build a network and can be used for training. This is slightly different from the usual "timing network", where the performance of the "timing network" is reduced as the number of layers increases.
5
ResNeXt
ResNeXt is said to be the most advanced object recognition technology to date. Based on inception and ResNet, ResNeXt is a new and improved network architecture. The following figure summarizes a residual module of ResNeXt:
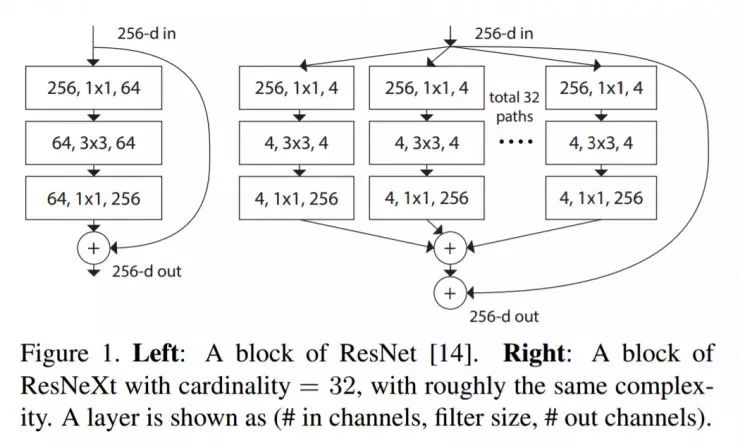
6
RCNN (Region Based CNN)
RCNN is said to be the most influential network architecture in the deep learning architecture for object recognition problems. To solve the identification detection problem, the RCNN attempts to frame all the objects in the image and then identify what the objects in the image are. The operation process is as follows:
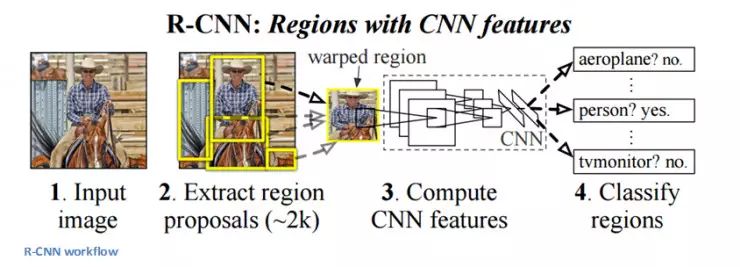
The structure of the RCNN is as follows:
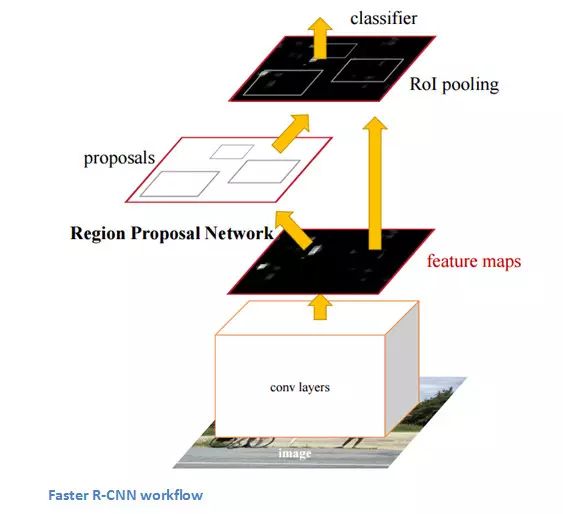
7
YOLO (You Only Look Once)
YOLO is by far the most advanced real-time image recognition system based on deep learning. As we can see in the image below, it first divides the image into small squares; then it runs the recognition algorithms one by one on these grids, determines what object type each grid belongs to, and then merges the squares of the same category. Get up and form the most accurate object frame. 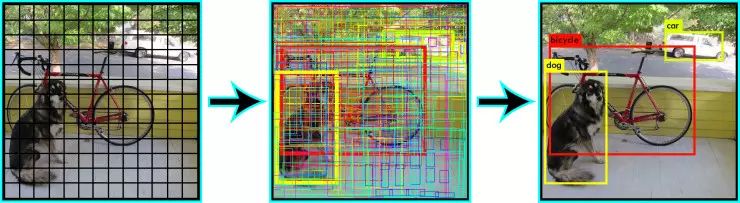
These operations are done independently, so they can be run in real time. A maximum of 40 images can be processed in one second.
Although YOLO's performance is reduced compared to its corresponding RCNN, its real-time processing capabilities still have significant advantages in dealing with everyday problems. The following is the YOLO network architecture:
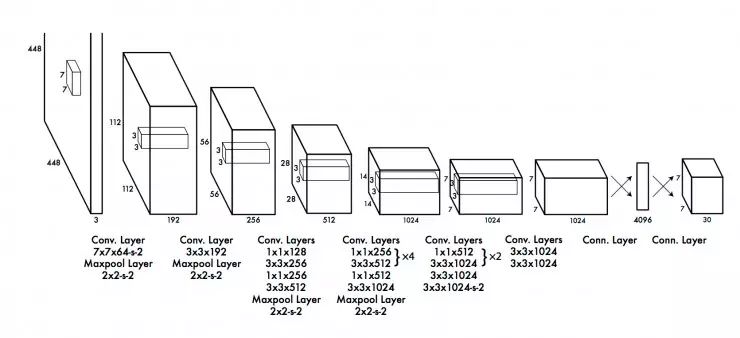
8
SqueezeNet
The SqueezeNet architecture is a more powerful network architecture that is very useful in low-bandwidth scenarios like mobile platforms. This network architecture only accounts for 4.9MB of space, while Inception accounts for more than 100MB. This remarkable change comes from a structure called the "fire module." The "fire module" is shown below: 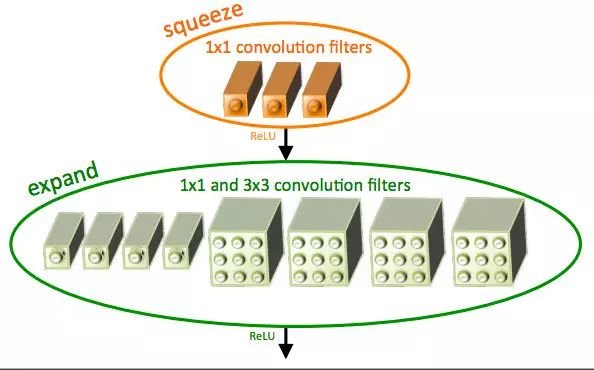
The following picture shows the final architecture of squeezeNet:
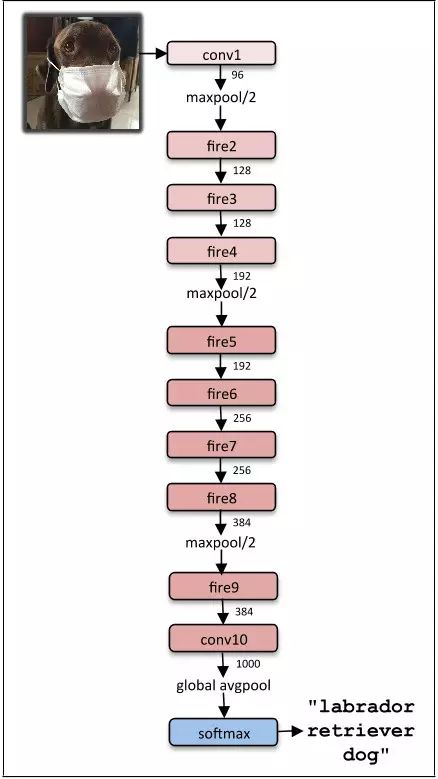
9
SegNet
SegNet is a deep learning architecture for image segmentation. It contains a series of processing layers (encoders) and a set of corresponding decoders for pixel classification. The following figure summarizes the operation of SegNet:
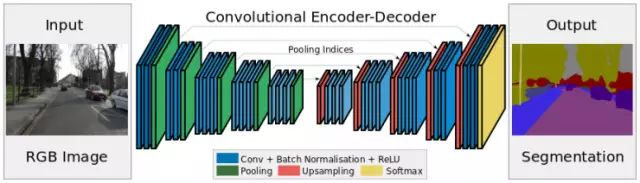
A key feature of SegNet is that high frequency details are preserved in the segmented image because the accumulation index of the coding network is interconnected with the accumulation index of the decoding network. In short, the transfer of information is straightforward, not through indirect convolution. SegNet is the best model for dealing with image segmentation problems.
10
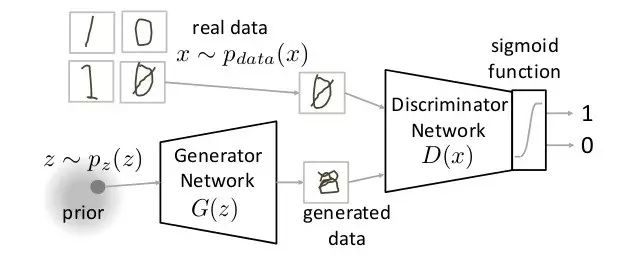
GAN (Generative Adversarial Network)
GAN is a completely different neural network architecture in which the neural network is used to generate a completely new image that does not exist. This image appears to have appeared in the training data set, but it does not. The figure below is an exploded view of the GAN.
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
Our products include disposable e-cigarettes, rechargeable e-cigarettes, rechargreable disposable vape pen, and various of flavors of cigarette cartridges. From 600puffs to 5000puffs, ZGAR bar Disposable offer high-tech R&D, E-cigarette improves battery capacity, We offer various of flavors and support customization. And printing designs can be customized. We have our own professional team and competitive quotations for any OEM or ODM works.
We supply OEM rechargeable disposable vape pen,OEM disposable electronic cigarette,ODM disposable vape pen,ODM disposable electronic cigarette,OEM/ODM vape pen e-cigarette,OEM/ODM atomizer device.

ZGAR Disposable Vape 25 Disposable Vape, bar 3000puffs,ZGAR Disposable Vape 25, Disposable E-cigarette, ZGAR Disposable Vape 25 OEM/ODM disposable vape pen atomizer Device E-cig, ZGAR 25 Vape
Zgar International (M) SDN BHD , https://www.zgarecigarette.com