Researchers from Google, Deepmind, and ETH Zurich have proposed a new method of "curiosity learning", which has changed the way the agent "curiosity" is generated and the reward mechanism. The reward mechanism is no longer based on the "accident" of the agent, but its Memory and context. Researchers claim that the new method can effectively reduce the bad behaviors of agents such as "going around in circles" and "procrastinating", and effectively improve the performance of the model.
Reinforcement learning is one of the most active research fields in machine learning. In the research environment of this field, artificial agents (agents) will receive positive rewards when they do the right thing, otherwise they will receive negative rewards.
This "carrot and stick" method is simple and universal. Professor DeepMind uses the DQN algorithm to play Atari games and AlphaGoZero to play Go, both using reinforcement learning models. The OpenAI team uses the OpenAI-Five algorithm to hit Dota. How Google teaches the robot arm to hold the new target is also achieved by reinforcement learning. However, despite the great success of reinforcement learning, there are still many challenges to make it an effective technique.
Standard reinforcement learning algorithms perform poorly in environments with little feedback from agents. Crucially, this type of environment is very common in the real world. For example, how to learn how to find your favorite cheese in a large labyrinth supermarket. You searched and searched, but you couldn't find a shelf for cheese.
If a certain step is completed, there is neither a "carrot" nor a "stick", then the agent cannot judge whether it is heading in the right direction. How can we avoid going around in circles when there is no reward? There is only curiosity, and curiosity will motivate the target to enter a seemingly unfamiliar area and find cheese there.
In a collaborative research between the Google Brain team, DeepMind, and ETH Zurich, a new model based on episodic memory was proposed, which can provide rewards similar to curiosity and can be used to explore the surrounding environment.
The research team hopes that the agent must not only be able to explore the environment, but also solve the original task, so the reward provided by the model is added to the original reward for tasks with sparse feedback information. The combined rewards are no longer sparse, and can learn from it using standard reinforcement learning algorithms. Therefore, the curiosity method proposed by the team expands the set of tasks that can be solved with reinforcement learning. The research paper is titled "Episodic Curiosity through Reachability"
Situation-based curiosity model: The observation result is added to the agent’s memory, and the reward is calculated based on the difference between the agent’s current observation result and the most similar result in the memory. The agent will receive more rewards for seeing observations that do not yet exist in the memory.
The key to this method is to store the agent's observations of the environment in episodic memory, and at the same time to reward the agent's observations of "not yet in memory" results. "Not in memory" is a new definition in this method. The agent seeks such observations, which means to seek unfamiliar things. The driving force of seeking strange things will allow the agent to reach a new location, prevent it from going around in circles, and ultimately help it find its goal. As will be discussed below, this method will not allow the agent to exhibit undesirable behaviors like some other methods, such as the "procrastination" behavior similar to humans.
Past curiosity learning mechanism: based on "accidental" curiosity
Although there have been many attempts to form curiosity in the past, this article focuses on a natural and very popular method: the mechanism of curiosity based on "accidents". This issue was discussed in a recent paper entitled "Curiosity-driven Exploration by Self-supervised Prediction". This method is generally called the ICM method. To illustrate how accidents arouse curiosity, here is again the analogy of finding cheese in a supermarket as an example.
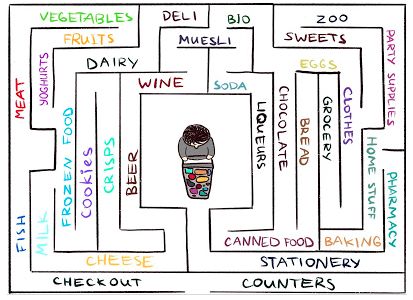
Imagine that when you are visiting the market, you are actually trying to predict the future ("Now I am at the meat stall, so I think there should be fish at the corner. In supermarket chains, these two parts are generally adjacent") . If your prediction is wrong, you will be surprised ("Ah, it turned out to be a vegetable seller. I didn't expect it!") and you will get a return. This makes you more motivated to pay more attention to corners in the future, explore new places, and see if your predictions are in line with reality (and hope to find cheese).
Similarly, the ICM method also establishes a predictive model of world dynamics, and rewards agents when the model fails to make good predictions. This reward marks an "accident" or "new thing." Note that exploring places you haven't been to is not a direct part of the ICM curiosity mechanism.
For the ICM method, this is just a way to get more "surprise", the purpose is to maximize the overall reward obtained. Facts have proved that there may be other ways to cause "self-accidents" in certain environments, leading to unpredictable results.
The intelligent experience based on "accidental" curiosity is stuck in front of the TV and does not perform tasks
Agents based on "accidental curiosity" are prone to "procrastinating behavior"
In the article "Large-Scale Study of Curiosity-Driven Learning", the authors of the ICM method and OpenAI researchers showed that reinforcement learning methods based on "accidental maximization" may have potential risks: agents can learn to indulge and procrastinate Behavior, don’t do anything useful to complete the current task.
In order to understand the reason, please see a common thought experiment called "Noisy TV Problem". In the experiment, the agent is placed in a maze, and the task is to find a very valuable item (same as before in this article). The "cheese" in the supermarket example is similar).
A TV is also placed in the test environment, and the smart body has a remote control for the TV. The number of TV channels is limited (each channel shows a different program), and each keystroke will switch to a random channel. How will the agent behave in such an environment?
For methods based on unexpected curiosity, changing channels can yield huge rewards, because every channel change is unpredictable and unexpected. What’s important is that even after the programs of all available channels recur once, because the content of the channel is random, each new change is still an accident, because the agent always predicts what program will be shown after the channel is changed. This prediction It is possible to make mistakes and cause accidents.
Even if the agent has watched every program on every channel, this random change is still unpredictable. Therefore, the unexpected curiosity agent will eventually stay in front of the TV forever and will not look for that very valuable item, which is similar to a kind of "procrastination" behavior. So, how to define "curiosity" to avoid this kind of procrastination?
Curiosity model based on "situation"
In the article "Episodic Curiositythrough Reachability", we explored a memory-based "situational curiosity" model, and the results proved that this model is not easy to produce "self-indulgence" instant gratification. why?
Here is an example of the above experiment. After the agent keeps changing the TV channel for a period of time, all the programs will eventually appear in the memory. As a result, television will no longer be attractive: even if the sequence of programs that appear on the screen is random and unpredictable, all these programs are already in memory.
This is the main difference between this method and the previous "accident-based" method: our method does not even predict the future. In contrast, the agent checks past information to find out whether it has seen and current observations. Therefore, our agents will not be attracted by the "instant gratification" provided by noisy TVs. It must go to the world outside of TV to explore in order to get more rewards.
How to judge whether the agent sees the same thing as the existing memory? It may be pointless to check whether the two match exactly: because in the real environment, the exact same scene rarely occurs. For example, even if the agent returns to the same room, its viewing angle will be different from the previous memory scene.
We will not check whether there is an exact match in the memory of the agent, but use the trained deep neural network to measure the similarity of the two experiences. In order to train the network, we will guess whether the two observations are very close in time. If the two are very close in time, they should probably be regarded as different parts of the same experience of the agent.
Whether it is new or old can be determined by the "reachability" graph. In practical applications, this picture is not available. We train a neural network estimator to estimate a series of steps between observations.
Experimental results and future prospects
In order to compare the performance of different methods, we tested in two 3D environments with rich visual elements: ViZDoom and DMLab respectively. In these environments, the task of the agent is to deal with various problems, such as searching for targets in a maze, or collecting "good targets" while avoiding "bad targets".
The DMLab environment just happens to provide a cool tool for the agent. In previous studies, the standard setting for DMLab is to equip the agent with gadgets that are suitable for all tasks. If the agent does not need gadgets for specific tasks, it can be omitted.
Interestingly, in a noisy TV experiment similar to the above, the accident-based ICM method actually used this gadget, even though it was useless for the current task! The task of the agent is to search for high-reward targets in the maze, but it prefers to spend time marking the walls because it will generate a lot of "unexpected" rewards.
In theory, it is possible to predict the marked results, but in practice it is too difficult to achieve, because the agent obviously does not have the deeper physical knowledge required to predict these results.
Based on the "accidental" ICM method, the agent has been marking the wall instead of exploring the maze
Our method learns reasonable exploratory behavior under the same conditions. The agent does not try to predict the result of its behavior, but seeks observations that are “harder†to achieve the goal from those already in the episodic memory. In other words, the intelligent body will search for more difficult goals based on memory, rather than just mark operations.
In our "episodic memory" method, the intelligent experience makes a reasonable exploration
What's interesting is that the reward mechanism implemented by our method will punish agents who go around in circles. This is because after completing a content cycle, the agent's subsequent observations are already in the memory, so they won't get any rewards:
Visualization of the reward mechanism of our method: red represents negative rewards, and green represents positive rewards. From left to right: use reward mapping, use current memory location mapping, first-person view
We hope that our research will help lead discussions on new methods of discovery. For an in-depth analysis of our method, please view the preprint of our research paper.
Wireless Sweatproof Earphone Bluetooth Headphones Bone Conduction Headset IP55 Waterproof
.
Companies registered capital of 35 million yuan, the end of 2014 the total assets of 48.69 million yuan, including fixed assets of 37.52 million yuan. The cothan another low way, so that more particles to have less than the activation energy of the reaction kinetic energy, thus speeding up the reaction rate. Enzyme as a catalyst, in itself is not consumed during the reaction, it does not affect the chemical equilibrium reactions. Positive enzyme catalysis, but also a negative catalytic effect, not only to accelerate the reaction rate, but also to reduce the reaction rate. And other non-living catalysts is different, having a high degree of specificity of enzyme, only a catalytic reaction or produce a particular specific configuration.test
.
Companies registered capital of 35 million yuan, the end of 2014 the total assets of 48.69 million yuan, including fixed assets of 37.52 million yuan. The cothan another low way, so that more particles to have less than the activation energy of the reaction kinetic energy, thus speeding up the reaction rate. Enzyme as a catalyst, in itself is not consumed during the reaction, it does not affect the chemical equilibrium reactions. Positive enzyme catalysis, but also a negative catalytic effect, not only to accelerate the reaction rate, but also to reduce the reaction rate. And other non-living catalysts is different, having a high degree of specificity of enzyme, only a catalytic reaction or produce a particular specific configuration.test
Wireless Sweatproof Earphon
2222Bossgoo(China)Tecgnology.
(Bossgoo(China)Tecgnology) , https://www.cn-gangdao.com