HBase is a Hadoop database, often described as a sparse, distributed, persistent, multidimensional ordered map that is indexed based on row keys, column keys, and timestamps. It is a randomly accessible storage and A platform for retrieving data. HBase does not limit the types of data stored, allowing dynamic, flexible data models without the SQL language or the relationship between data. HBase is designed to run on a server cluster and scale out accordingly.
HBase usage scenarios and success storiesInternet search problem: The crawler collects the webpage and stores it in the BigTable. The MapReduce computing job scans the entire table to generate a search index, and queries the search result from the BigTable to display it to the user.
Grab incremental data: for example, crawling monitoring metrics, crawling user interaction data, telemetry, targeted advertising, etc.
Content service
Information exchange
getting Started
1, API
There are five HBase APIs related to data operations, namely Get, Read, Delete, Scan, and Increment.
2, the operation table
First create a configuraTIon object
ConfiguraTIon conf = HBaseConfiguraTIon.create();
When using eclipse, you must also add the configuration file.
conf.addResource(new Path("E:\\share\\hbase-site.xml"));
conf.addResource(new Path("E:\\share\\core-site.xml"));
conf.addResource(new Path("E:\\share\\hdfs-site.xml"));
Create a table using the connection pool.
HTablePool pool = new HTablePool(conf,1);
HTableInterface usersTable = pool.getTable("users");
3, write operation
The command used to store data is put. To store data in the table, you need to create a Put instance. And make the line to join
Put put = new Put(byte[] row) ;
Put's add method is used to add data, respectively set the column family, qualifiers and cell pointers
Put.add(byte[] family , byte[] qualifier , byte[] value) ;
Finally submit the order to the table
usersTable.put(put);
usersTable.close();
To modify the data, simply resubmit the latest data.
The working mechanism of HBase write operation:
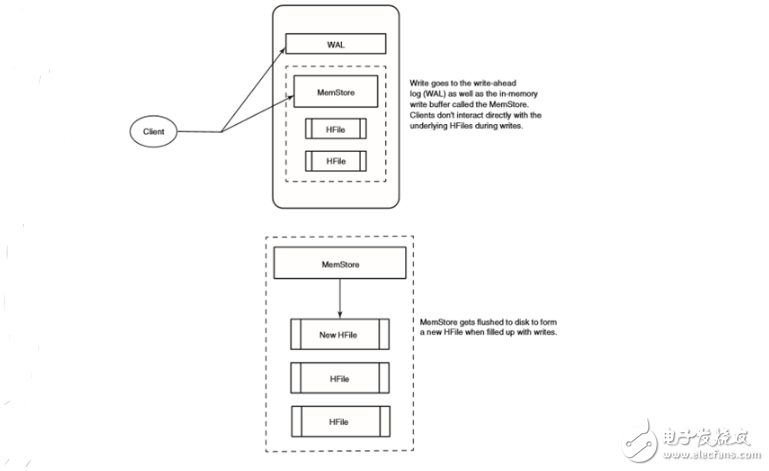
Each time HBase performs a write operation, it will be written to two places: write-ahead log (also called HLog) and MemStore (write buffer) to ensure data persistence, only when the two places change. After the information is written and confirmed, the write action is considered complete. MemStore is a write buffer in memory. The data in HBase is accumulated here before it is permanently written to the hard disk. When MemStore is filled, the data will be written to the hard disk to generate an HFile.
4, read operation
Create a Get command instance containing the rows to be queried
Get get = new Get(byte[] row) ;
Execute addColumn() or addFamily() to set the limit.
Submitting a get instance to a table returns a Result instance containing the data, which contains all the columns of all column families in the row.
Result r = usersTable.get(get) ;
You can retrieve a specific value for the result instance
Byte[] b = r.getValue(byte[] family , byte[] qualifier) ​​;
Working Mechanism:
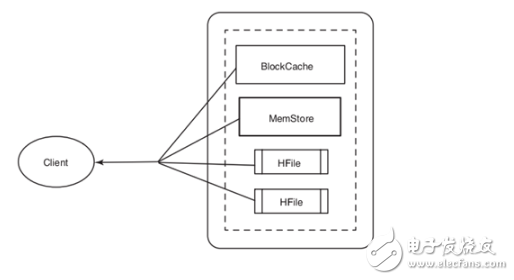
BlockCache is used to store frequently accessed data read into memory from HFile, to avoid hard disk read, each column family has its own BlockCache. Reading a row from HBase first checks the queue that MemStore is waiting to modify, then checks BlockCache to see if the block containing the row has been accessed recently, and finally accesses the corresponding HFile on the hard disk.
5, delete the operation
Create a Delete instance specifying the row to delete.
Delete delete = new Delete(byte[] row) ;
Part of deleting a row can be specified by the deleteFamily() and deleteColumn() methods.
6 table scan operation
Scan scan = new Scan() can specify the start and end lines.
The setStartRow() , setStopRow() , setFilter() methods can be used to limit the data returned.
The addColumn() and addFamily() methods can also specify columns and column families.
The data model of HBase mode includes:Table: HBase uses tables to organize data.
Line: In the table, the data is stored in rows, and the rows are uniquely identified by row keys. The row key has no data type and is a byte array byte[].
Column family: The data in the row is grouped by column family, which must be defined in advance and not easily modified. Each row in the table has the same column family.
Column qualifiers: Data in a column family is located by column qualifiers or columns, and column qualifiers do not have to be defined beforehand.
Unit: The data stored in the unit is called the unit value, and the value is the byte array. Cells are determined by row keys, column families, or column qualifiers.
Time version: The unit value has a time version and is a long type.
An example of HBase data coordinates:
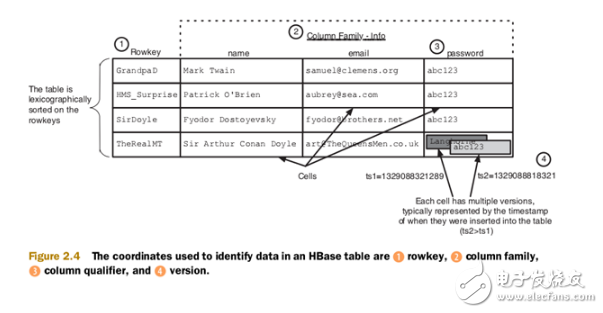
HBase can be seen as a key-value database. HBase is designed for semi-structured data, and data records may contain inconsistent columns, indeterminate sizes, and so on.
Third, distributed HBase, HDFS and MapReduce
1, distributed mode HBase
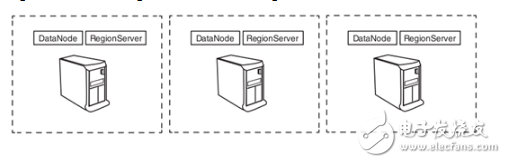
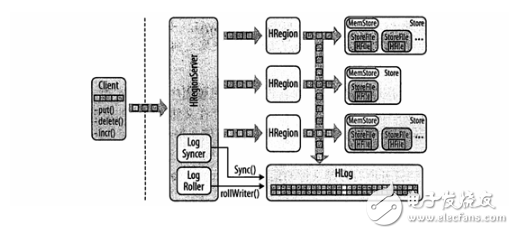
HBase divides the table into small data units called regions and allocates them to multiple servers. The server hosting the region is called RegionServer. In general, RgionServer and HDFS DataNode are configured side by side on the same physical hardware. RegionServer is essentially an HDFS client, where access data is stored. HMaster allocates a region to RegionServer, and each RegionServer hosts multiple regions.
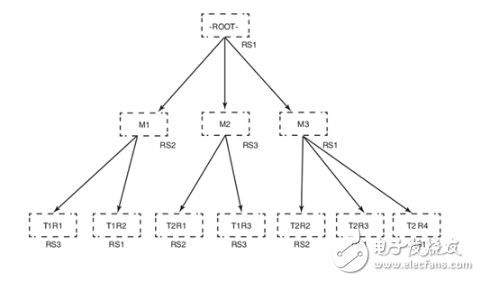
Two special tables in HBase, -ROOT- and .META., are used to find out where the regions of the various tables are located. -ROOT - points to the region of the .META. table. The .META. table points to the RegionServer hosting the region to be searched.
The 3-layer distributed B+ tree of a client lookup process is as follows:
HBase top-level structure diagram:
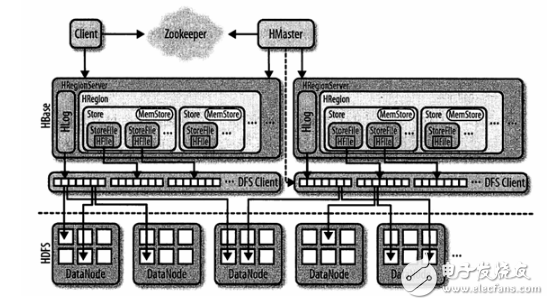
The zookeeper is responsible for tracking the region server and saving the address of the root region.
The client is responsible for contacting the zookeeper subcluster and the HRegionServer.
HMaster is responsible for assigning all regions to each HRegion Server when starting HBase, including the -ROOT- and .META. tables.
HRegionServer is responsible for opening the region and creating the corresponding HRegion instance. After HRegion is opened, it creates a Store instance for each table's HColumnFamily. Each Store instance contains one or more StoreFile instances, which are lightweight wrappers for the actual data store file HFile. Each store has its own one MemStore, and one HRegionServer shares an HLog instance.
A basic process:
a. The client obtains the region server name containing -ROOT- through zookeeper.
b. Query the region server name corresponding to the .META. table by using the region server containing -ROOT-.
c. Query the .META. server to obtain the region server name where the row key data of the client query is located.
d. Obtain data by the region server where the row key data is located.
HFile structure diagram:
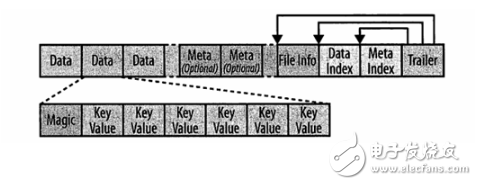
Trailer has pointers to other blocks, Index blocks record offsets for Data and Meta blocks, and Data and Meta blocks store data. The default size is 64KB. Each block contains a Magic header and a number of serialized KeyValue instances.
KeyValue format:
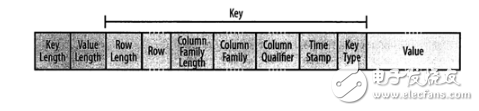
The structure begins with two fixed-length numbers that represent the length of the key and the length of the value. The key contains the row key, column family name and column qualifier, timestamp, and so on.
Write-ahead log WAL:
Each update is written to the log, and only if the write is successful will the client be notified that the operation is successful, and then the server can freely batch process or aggregate the data in memory as needed.
The process of editing the flow between the memstore and the WAL:
Processing: The client sends an instance of the KeyValue object to the HRegionServer containing the matching region through an RPC call. These instances are then sent to the HRegion instance that manages the corresponding row, the data is written to the WAL, and then placed into the MemStore of the storage file that actually owns the record. When the data in the memstore reaches a certain size, the data is continuously written to the file system asynchronously, and the WAL can ensure that the data of this process is not lost.
1. Why introduce a coprocessor?In the old version (before the 0.92HBase version), there was no concept of introducing a coprocessor. The problem with this is that it is difficult to create a secondary index, and it is difficult to perform simple sorting, summation, counting, and the like. This means that it is difficult to perform the above operations under the restrictions of this version, not not. In order to reduce the difficulty, the concept of coprocessor is proposed.
Here add the knowledge points related to the index:
The concept of indexing:
i) Clearly for the database, it is a table or a data structure, one or more columns, for the purpose of quickly accessing information in the database. The content contained is: the attribute value of the key and a pointer to the file location information.
Ii) Main index:
The primary index is an ordered file containing two fixed length fields. Field 1: Primary Key; Field 2: Pointer to the disk block. The values ​​of these two fields are the values ​​of the index entries.
Ii) secondary index
The concept of secondary index:
"The secondary index is also an ordered file with two fields:
The first field is the index field, has the same data type, and is a non-sorted field in the data file.
The second field can be either a block pointer or a record pointer. A secondary index (also known as a nonclustered index) is used to search for files on a secondary key, and a search key for a secondary index specifies an order that is different from the sort order of the files. â€
2. What are the characteristics of the coprocessor?Allows users to perform region-level operations, using trigger-like functions
Allow extension of existing RPC protocol to introduce its own calls
Provide a very flexible data model that can be used to build distributed services
Ability to automate scaling, load balancing, and application request routing
3. Coprocessor usage scenarios:Maintain secondary indexes; maintain application integrity between data.
4. The coprocessor framework provides two major classes of Observer and endPoint (the following is the third edition of the HBase Authoritative Guide)Extend your capabilities by inheriting these two categories.
1) Observer (observer)
This class is similar to the trigger in RDMS. The callback function is called when certain events occur.
Events include: events generated by the user or events generated internally by the server.
The interfaces provided by the coprocessor framework are as follows:
a, RegionObserver: Users can handle data modification events through this processor, they are closely related to the Region of the table. Region level operation. The corresponding operation is: put/delete/scan/get
b, MasterObserver: can be used as a management or DDL type of operation, is a cluster-level operation. The corresponding operation is: create, delete, modify the table.
c, WALObserver: Provides a hook function that controls the WAL.
Observer defines a hook function that the server can call.
2) endPoint
The functionality of this class is similar to the stored procedure in RDMS. Adding user-defined actions to the server side, endPoint can extend the RPC protocol by adding remote procedure calls. Users can deploy custom code to the server side. For example: server-side computing operations.
When used together, the state of the server can be determined.
5, Coprocessor classAll coprocessors must be implemented to an interface that defines the basic conventions of the coprocessor and ease of frame management, and defines the priority level of execution of the coprocessor.
1) Coprocessor execution order
The Coprocessor.Priority enumeration type defines two values: SYSTEM, USER. The former is better than the latter, and the latter is defined in order.
2) The life cycle of the coprocessor
The life cycle of the coprocessor is managed by the framework. The interface defines two methods, start and stop. The parameters of these two methods are: CoprocessorEnvironment. This class provides methods for accessing HBase versions, Coprocessor versions, coprocessor priorities, and more. The start/stop method is implicitly called, and the definition of the state of the coprocessor is corresponding to an enumeration class Coprocessor.State.
3) Maintenance of coprocessor environment and instance
The CoprocessorHost class is implemented, and it has subclasses to complete the maintenance of the region, the master coprocessor instance and the environment.
Summary: Coprocessor, CoprocessorEnvironment, CoprocessorHost are three classes, based on the three classes to expand the function, complete support, management, maintenance coprocessor.
6, coprocessor loading / deploymentThere are two ways to load the processor: 1. Static loading through the configuration file 2. Dynamic loading during the cluster runtime (in the third edition of the authoritative guide, there is no dynamically loaded API).
1) For static loading
In the HBase authoritative guide, P171 points out that it is not repeated here, it is the hard work of moving bricks. What needs to be emphasized is that the order of the configuration items in the configuration file is very important in the book. This order determines the execution order.
2) The specific table loading processor is attributed to the static loading method
Coprocessor loading for a particular table is through a table descriptor. Therefore, the loading of the processor is only for the region of the table, and is called by the region and the region server of the server, and cannot be called by the master or the WAL. An example is given in P173 of the HBase Authoritative Guide.
7, RegionObserver classDescription of the class: 1. The RegionObserver class is a subclass of the Observer class 2. It is explicitly in response to the region level operation. When a region event occurs, its defined hook function is called. This level of operation can be divided into two categories: region lifecycle changes or client API calls.
1) Processing region life cycle events
The life cycle event here reflects the state change of the region, and the time of the trigger processing occurs before and after the state change.
The following are coprocessors that can be defined before and after different states (the coprocessor here refers to the operations that can be performed):
State 1: pendingOpen, the state in which the region will be opened.
The way the coprocessor is implemented is:
preOpen()/postOpen(). The completion function is: piggybacking or blocking the opening process.
The function completed by preWALRestore()/postWALRestore. is that the user can access those records that have been modified to supervise which records have been implemented.
State 2: open, the flag for this state is: when the region is deployed to a region server and is working properly.
The methods that the coprocessor can implement are:
Void preFlush()/void postFlush() memory is persisted to disk
Void preSpilt()/void postSpilt() when the region is large enough to split
State 3: pendingClose. The state when the region will be closed.
The methods that the coprocessor can implement are:
Void preClose()/void postClose()
2) Handling client API events
Here is the event that responds when the Java API is called. Such as:
Void prePut()/void postPut, void preDelete()/postDelete(), void preGet()/void postGet(). . . . . . . .
3) RegionCoprocessorEnvironment class
The coprocessor environment class that implements the RegionObserver class is based on the RegionCoprocessorEnvironment class, which allows access to the management Region instance and the shared RegionServerService instance.
4) ObserverContext
All callback functions provided by the RegionObserver class require a special context as a common parameter. The ObserverContext class provides access to the current system environment, and also adds some key features to inform the coprocessor framework what to do when it returns to completion. The byPass()/complete() method is explained, the former stops the current service process processing, and the latter affects the coprocessor that is executed later.
5) BaseRegionObserver class
The role of this class is: it can be used as a base class for implementing all listener type coprocessors. It's important to note that in order to implement custom functions, you must override the methods of this class.
8, MasterObserver classThe coprocessor definition is defined as all callback functions for the master server. The operations in these callback functions are similar to DDL, creating, deleting, and modifying tables.
1) MasterCoprocessorEnvironment
The MasterCoprocessorEnvironment encapsulates the MasterObserver instance, which allows access to the MasterService instance.
2) BaseMasterServer
BaseMasterServer is an empty implementation of MasterServer, which can be customized by implementing the corresponding pre/post. For example: void preCreateTable()/void postCreateTable() void preDeleteTable()/void postDeleteTable(). . . . . .
9, endPointWhat is the reason for endPoint?
CoprocessorProtocol interface
The interface allows the user to customize the RPC protocol, its implementation code is installed on the server, and the client HTable provides a calling method that can be used to communicate with the coprocessor instance.
Bakelite Material,Bakelite Plastic,Bakelite Made From,Bakelite Synthetics
WENZHOU TENGCAI ELECTRIC CO.,LTD , https://www.tengcaielectric.com