In recent years, machine learning has achieved outstanding results in the fields of search, advertising, and recommendation, and has become one of the most eye-catching technology hotspots. Weibo has also made extensive explorations in machine learning. Among them, in the recommended field, machine learning technology is applied to one of Weibo's most important products, popular microblog, and has achieved remarkable improvement.
Popular Weibo recommendation system introduction
Popular Weibo business scene
Popular Weibo is a personalized interest reading product based on Weibo's native content. Provide the latest hottest and high-quality content reading service to better protect users' reading efficiency and quality, and at the same time, to stimulate the content authors to create and promote content on Weibo.
The recommendation system of popular Weibo mainly faces the following two challenges.
Large-scale: need to deal with massive users and massive content on Weibo;
Timeliness: The production cycle of Weibo content is short and changes rapidly.
Popular Weibo recommendation system algorithm flow
We have customized a comprehensive recommendation system framework, including machine learning-based multi-channel recall and sequencing strategies, and recommendation engines from off-line computing of massive big data to high concurrent online services. The recommendation system is mainly divided into three layers, the basic layer, the recommendation (recall) and the sorting. The recommendation (recall) is mainly responsible for generating the recommended candidate set, and the ranking is responsible for personalizing the results of the multiple algorithm strategies.
The overall recommended technical framework is shown in Figure 1.
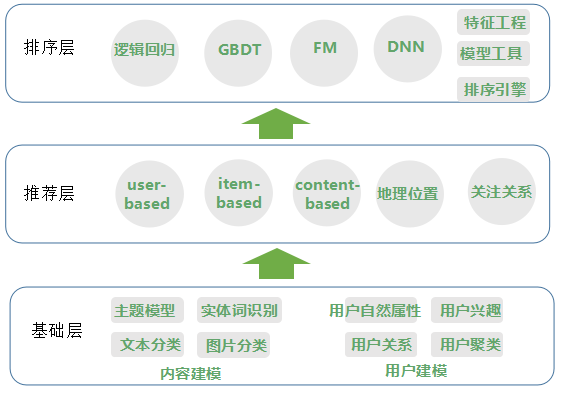
Figure 1 Top Weibo Recommended Technology Framework
The base layer: divided into two parts: content modeling and user modeling. Content modeling is mainly the semantic recognition of Weibo content, including topic model, entity word recognition, text classification and image classification. User modeling creates a complete picture of the user, including the user's natural attributes (gender/age), user interests, user clustering, and relationships between users (intimacy, etc.).
Recommendation layer: We conduct real-time judgment through user behavior, Weibo content, etc., and obtain different candidate sets through multiple recall algorithms. The candidate sets of the recall are merged. The specific recall algorithm is as follows:
User-based collaborative recommendation: Find the N users that are most similar to the current User X, and score the item according to the N user's score estimation for an Item.
Item-based collaborative recommendation: We calculate the co-occurrence probability of different mid, and take out the mid that meets a certain threshold and is ranked as the candidate for the synergy mid.
Content-based recommendation: Labels microblog text, images, videos, etc. through natural language processing, image recognition and other algorithms; mine user interest tags through user behavior and microblog content tags. A content-based recommendation candidate is provided based on the matching of the content tag and the interest tag.
Sorting layer: Each type of recall strategy will recall certain candidate microblogs. These candidate microblogs need to be uniformly sorted after being deduplicated. The models used for sorting include logistic regression, GBDT/FM, DNN, and so on. The sorting framework can be roughly divided into three parts:
Feature engineering: feature preprocessing, discretization, normalization, feature combination, etc., to generate sample data needed for the training model.
Model tool: Based on sample data, use different models to train, evaluate, and generate model training results.
Sorting engine: The online model LOAD extracts the corresponding features and performs feature mapping, and uses the machine learning sorting algorithm to fuse and score the recommended candidates for multi-policy recall.
Popular Weibo's machine learning recommendation
Collaborative filtering recommendation is one of the commonly used recommendation algorithms in the industry. Collaborative filtering recommendation is a type of algorithm that uses the relationship matrix of users and items to model user and item. It is mainly divided into two types: user-based collaborative filtering recommendation and item-based collaborative filtering recommendation. In the popular Weibo business scenario, an item refers to a Weibo. The following describes the practice of user-based collaborative filtering recommendation and Weibo-based collaborative filtering recommendation.
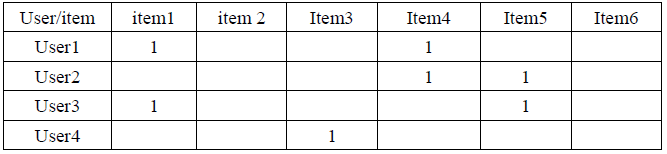
Table 1 User-Item Relationship Matrix
Large-scale user-based collaborative recommendation
The basic principle of user-based system filtering recommendation is: what a user's similar user group likes, what to recommend to the user.
In practice, the user-based system filtering recommendation process is the following steps:
Find his similar user group for the current user;
Obtaining a number of Weibos that the user group likes during the historical period as candidates;
Calculating the preference of the user group for each candidate microblog;
Recommend the N favorite microblogs with the highest preference to the current user.
Among the above steps, the most critical is a. The user's similarity degree directly affects the accuracy of the recommendation; the size of the user's similar user group directly affects the degree of personalization of the recommendation. There are many schemes for similar user groups, and there are clusters and K neighbors. Their advantages and disadvantages are compared as follows.
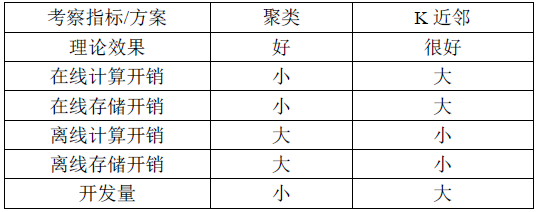
Table 2 Comparison of clustering and K-nearest neighbor schemes
Finally, according to our business scenario, we chose a clustering scheme. Given the nature of the business, we also have additional requirements for clustering results: the number of quality users included in each category should be as close as possible. Our solution is to train only with high-quality users while ensuring even clustering, and all users make predictions. So the next problem to be solved is to choose the clustering algorithm, the user's vector representation, and control the clustering uniformity.
Although there are many clustering algorithms, they are still basically in the framework of K-Means algorithm, so we directly use the K-Means algorithm. About representing a user with a mathematical vector. It is worth noting that when solving the actual clustering problem, in general, the vector representation of the problem object has a greater impact on the final effect than the clustering algorithm itself.
First, we consider using the row vector of the relation matrix directly as the vector representation of the user. In the scenario recommended by Weibo, the number of items is increasing rapidly, so only the user-microblog relationship matrix in history can be used. At the same time, the matrix is ​​sparsely clustered. When we train clusters with shorter historical data, the effect is not good. Therefore, we try to lengthen the history to ensure that the user vector contains sufficient information. However, K-Means is extremely inefficient in training high-dimensional data. We try to balance the training efficiency and clustering effect, but the effect is very poor, and the scale of each category is extremely uneven and cannot meet the demand.
Therefore, we considered three dimensionality reduction schemes: LDA, Word2Vec, and Doc2Vec.
LDA: Although the theme distribution of LDA training can be used as a feature vector, LDA itself does not emphasize the concept of distance between vectors, which can not match the training process of the K-Means algorithm, so the effect is not good and eliminated.
Word2Vec: emphasizes the distance between vectors, suitable for K-means. But when using Word2Vec, we want the Weibo ID to be the sentence ID, the reader sequence of Weibo as the sentence content, and the user ID as the word. According to the characteristics of Weibo, the distribution of the "sentence" length in the corpus will be very uneven. So there is no choice in the end.
Doc2Vec: Emphasizes the distance between vectors, suitable for K-means. When the user ID is taken as the sentence ID and the user's reading sequence is used as the sentence content, and the microblog ID is trained as a word, the distribution of the "sentence" length in the corpus is much more uniform and the effect is better.
So I finally chose Doc2Vec to reduce the user vector. Then use low-dimensional vectors for clustering, the results are significantly improved, the category size becomes very uniform, in line with our needs.
In the online part, the online part only needs to record the behavior of the user groups under each cluster for each microblog within a few hours, after simple weighting calculation, sorting, and taking Top. When recommending for a user, it is only necessary to find a recommendation list corresponding to the corresponding cluster ID. Online computing overhead is minimal.
Large-scale item-based collaborative recommendation
The basic principle of Weibo-based collaborative filtering recommendation is: If a large percentage of users who have seen Weibo A go to Weibo B, then Weibo B should be recommended to users who only see Weibo A. The realization of this principle is to calculate the correlation of any two microblogs. Design correlation formulas at key points. We iterated three versions of the correlation formula.
In the first edition, we abstracted the correlation as:
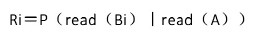
The specific implementation is to calculate the correlation between the two microblogs according to the above formula, and then select the relevant microblog for each microblog according to the preset threshold excerpt. This can recommend a list of related Weibos for instant recommendation modules. When the user clicks on a certain Weibo, the related Weibo of the Weibo will be recommended at the next refresh. Because the content of Weibo is more effective, this recommendation method can capture the user's timely reading requirements, so the accuracy of recommendation is very high. However, the recall rate of the above method is relatively low.
The second edition focuses on improving the recall rate. The analysis found that the reason for the low recall rate is that the user-microblog matrix is ​​particularly sparse, and the number of co-occurrences of two microblogs in a user's browsing is particularly small. So a new formula was designed:
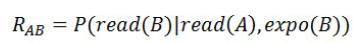
In the formula we added the variable expo(B), which means that B is exposed in the user's page. After the implementation of the new formula, the recall has increased significantly.
In the third edition, we tried to solve the problem of sparse relation matrix. In the Weibo scene, many Weibos are similar, but they have different Weibo IDs. This naturally causes the matrix to be sparse and the correlation calculation is inaccurate. for example:
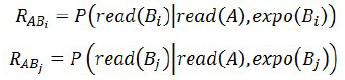
Assuming that Bi and Bj are the same content described, and both RABi and RABj are slightly below the threshold, then Bi and Bj are collaborative recommendation microblogs that cannot be used as A, which is obviously unreasonable.
To solve this problem, we have improved the algorithm. First, similar microblogs Bi and Bj are aggregated into B, and then the correlation is calculated. The process is as follows:
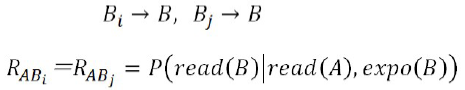
After the improvement, the coverage rate has been further improved.
Popular Weibo machine learning sorting
Machine learning sorting is the core algorithm of search, advertising, recommendation and other business scenarios, and has a great impact on business results. The usual practice is to collect various features based on exposure logs, click logs, etc., to model user click-through rates. In the popular Weibo business, the following are some of our effective practices in sorting algorithms.
Large-scale feature combination
A central factor affecting the ordering of machine learning is the feature. Especially when using linear models (such as logistic regression), the effect of the model is greater, is the combination of features, that is, the ability to express features.

Figure 2 Feature space of the sorting model
As shown in Figure 2, the ranking model can be thought of as a three-dimensional feature space built on materials, users, and environments. In each dimension, the direction from the zero point represents the specific to the generalization. For example, the material axis starts from zero, and the material is divided into mid (microblog id), fine-grained label, coarse-grained label, author, and form.
According to the practice in popular Weibo, some design experiences and principles of feature combination are summarized:
The more the feature is closer to zero, the more effective it is, but the sparsity is considered.
A combination of features across axes will result in more personalized features, especially a combination of user and material.
Multi-objective machine learning sorting
The usual ctr prediction order is only targeted at the click rate. The popular Weibo business has multiple goals, so you need to consider multi-target sorting. Practice has shown that there is often no strong positive correlation between multiple objectives. Therefore, it is very important to balance the multiple goals in the ranking model so that each goal grows. In the machine learning sorting of popular Weibo, we experimented with two methods:
Each target uses a model to model fusion. For example, popular Weibo needs to consider forwarding, commenting, and praise. The models that predict the forwarding rate model, the estimated comment rate, and the estimated rate are trained respectively. The prediction results of the three models are weighted and used as the sorting score.
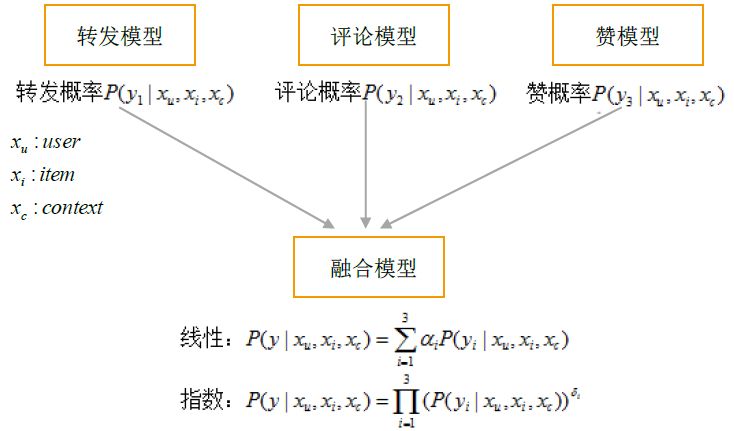
Figure 3 Fusion of multi-objective machine learning models
After the model is merged, the probability of raising all positive behaviors is taken as the overall goal, and each model is assigned different weights. The advantage of this method is that different targets are modeled separately, and weights are adjusted in quick sets of experiments to find a better solution of the weight parameters. The disadvantage is that multiple models need to be trained at the same time, and the development cost is high.
Use one model for all targets and consider multiple targets when labeling positive samples. For example, for forward and praise, when labeling positive samples, give different weights so that they are integrated into the model target. As shown in Table 3, for each training sample, the weights of forwarding, commenting, and praise are set to 1, 2, and 5, respectively, according to business needs.
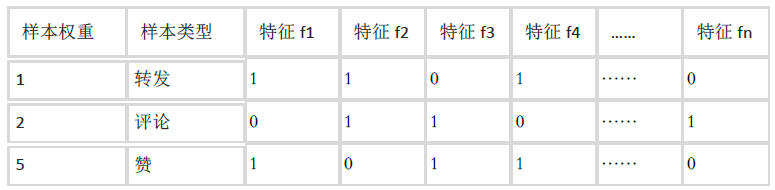
Table 3 Labels different weights by sample, one model takes into account multiple targets
The method converts multi-objective problems into single-objective problems by giving different weights to different positive behaviors. Its advantage is that a model takes into account multiple targets at the same time, so that the weights of different targets are reflected in the loss function, and the model is optimized to solve the problem, which is convenient for balancing multiple targets.
Slice linear model
A linear model is widely used in machine learning algorithms in the Internet industry. The disadvantage of the linear model is that it cannot fully utilize the nonlinear laws in the data.
Under the popular Weibo, the click rate and behavior preference of different users are different, and the click rate in different material fields is also different. Therefore, we consider using user-based, domain-based prior knowledge to construct a linear model of the fragment. .
In addition, the fragmented linear model of popular Weibo combines multi-objective optimization. According to the behavioral preferences of different groups of people, different multi-target weights are set at the time of sharding.
Slice linear model:

Where πi is the range of the slice, which is 1 for the slice and 0 for the other.
In the popular Weibo business, the shards are different groups (80/90, male/female).
Fragmented multi-objective model (exponential weighting as an example):
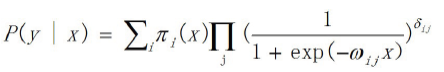
Where πi is the range of the slice, ωij is the parameter of the jth target model in i slices, and δij is the index weight of the jth target model in the i-th slice.
Machine learning effect evaluation
For collaborative filtering recommendations, we designed a measure m to simulate the actual effect after estimating the line. Suppose there is a historical log of N+1 days. First, the user-microblogging matrix of 1-N days is used to calculate the candidate microblog set C for the N+1th collaborative recommendation for each user. Then, the real exposure microblog set E of the N+1th day is intersected with C to obtain the set Ec; the real click microblog set A of the N+1th day is intersected with C to obtain the set Ac. Finally, Ac/Ec is calculated as a measure.
For the sorting algorithm, an offline AUC assessment and an online ABTest assessment are used.
After the machine learning was applied to the popular Weibo recommendation system, the business indicators and user experience were significantly improved.
Summary and outlook
We applied machine learning related technology to popular Weibo business, and further expanded the algorithm based on business characteristics.
In terms of recommendation algorithms, user-based collaborative filtering recommends that we use the user embedding+Kmeans scheme to balance algorithmic effects, off-line computational scale, and online response speed. Based on Weibo-based collaborative filtering, we have upgraded two correlation calculation formulas to solve the problem of sparse data caused by sparse behavior and duplicate content.
In terms of sorting algorithms, some rules and principles summarized in the feature engineering practice of large-scale feature combination, multi-objective machine learning sorting is an attempt and exploration to balance multiple business objectives. The piecewise linear model is combined with popular microblogging business knowledge. Improve the structure and effect of the linear model.
Capillary Of Thermometer,Bourdon Gauge Thermometer,Capillary In Thermometer,Thermometer Pressure Gauge
ZHOUSHAN JIAERLING METER CO.,LTD , https://www.zsjrlmeter.com