Xilinx INT8 optimization provides the best performing and most energy efficient computing technology for deep learning inference. Xilinx's integrated DSP architecture delivers 1.75x solution-level performance on INT8 deep learning operations compared to other FPGA DSP architectures.
summaryThis white paper is designed to explore the implementation of INT8 deep learning on the Xilinx DSP48E2 slice and compare it to other FPGAs. With the same amount of resources, Xilinx's DSP architecture achieves 1.75x peak solution-level performance with INT8 on INT8 deep learning operations per second (OPS) compared to other FPGAs. Because deep learning inference can use lower bit precision without sacrificing accuracy, an efficient INT8 implementation is required.
Xilinx's DSP architecture and libraries are optimized for INT8 deep learning inference. This white paper describes how to use the DSP48E2 in Xilinx UltraScale and UltraScale+ FPGAs to handle two parallel INT8 multiply-accumulate (MACC) operations while sharing the same core weight. This white paper also explains why using the unique Xilinx technology, the minimum bit width of the input is 24 bits. This white paper also uses INT8 optimization technology as an example to demonstrate the correlation between this technology and the basic operations of neural networks.
INT8 for deep learningDeep Neural Networks (DNN) have revolutionized the field of machine learning while redefining many existing applications with new human-level AI capabilities.
As more precise deep learning models are developed, their complexity also presents challenges in terms of high computational intensity and high memory bandwidth. Energy efficiency is driving deep learning to infer new-pattern development innovations that require less computational power and memory bandwidth, but at the expense of accuracy and throughput. Reducing this overhead will ultimately improve energy efficiency and reduce the total power consumption required.
In addition to saving power during the calculation process, lower bit width calculations can also reduce the power consumption required for memory bandwidth because the number of bits transferred is reduced with the same number of memory transactions.
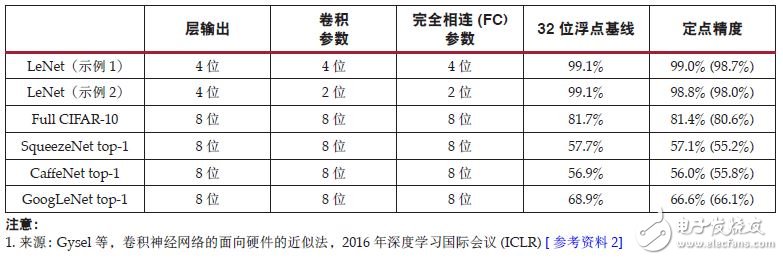
Studies have shown that to maintain the same accuracy, no deep floating learning is required for floating point calculations [Reference 1] [Reference 2] [Reference 3], and many applications such as image classification require only INT8 or lower fixed point calculation accuracy to maintain Acceptable inference accuracy [Reference 2] [Reference 3]. Table 1 lists the fine-tuned networks and the dynamic fixed-point parameters and outputs of the convolutional and fully connected layers. The numbers in parentheses represent unadjusted accuracy.
Table 1: CNN Model with Fixed Point Accuracy
Xilinx's DSP48E2 is designed to efficiently perform a multiply-accumulate algorithm in one clock cycle, up to 18x27 bits of multiplication and up to 48 bits of accumulation, as shown in Figure 1. In addition to loopback or linking multiple DSP slices, Multiply Accumulate (MACC) can also be done efficiently with Xilinx devices.
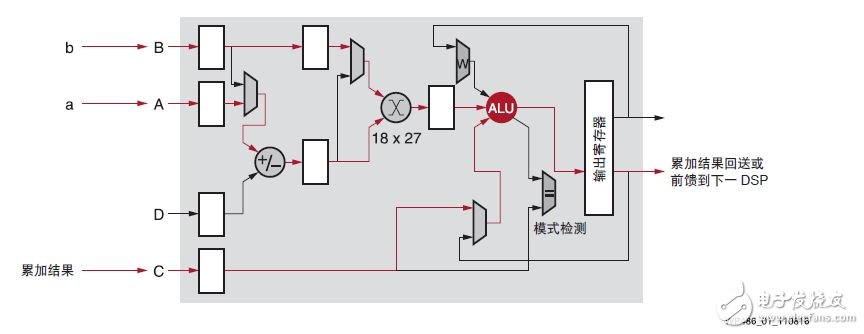
Figure 1: DSP Slice Using MACC Mode
The wider 27-bit width is inherently advantageous when running INT8 calculations. In traditional applications, pre-adders are typically used to efficiently implement (A+B) x C calculations, but such calculations are rare in deep learning applications. The result of (A+B) x C is split into A x C and B x C and then accumulated in separate data streams to make it suitable for typical deep learning calculations.
For INT8 deep learning operations, having an 18x27-bit multiplier is dominant. At least one of the multiplier inputs must be a minimum of 24 bits, and the carry accumulator must be 32 bits wide to perform two INT8 MACC operations simultaneously on a single DSP slice. The 27-bit input can be combined with a 48-bit accumulator to increase the depth learning solution performance by 1.75 times (1.75:1 is the ratio of the DSP multiplier to the INT8 deep learning MACC). FPGAs from other vendors offer only 18x19 multipliers in a single DSP block, and the ratio of DSP multiplier to INT8 MACC is only 1:1.
Scalable INT8 optimizationThe goal is to find a way to efficiently encode inputs a, b, and c so that the multiplication results between a, b, and c can be easily broken down into axc and bxc.
In lower precision calculations, such as INT8 multiplication, the upper 10 or 19 digit inputs are padded with 0 or 1 and carry only 1 bit of information. The same is true for the high 29 bits of the final 45-bit product. Therefore, another calculation can be performed using the upper 19 bits without affecting the lower 8-bit or 16-bit input.
In general, there are two rules that must be followed to use an unused high bit for another calculation:
1. The high position should not affect the calculation of the low position.
2. Any effect of the low level calculation on the high position must be detectable and possibly recoverable.
Power 90W ,output voltage 15-24V, output current Max 6A, 10 dc tips.
We can meet your specific requirement of the products, like label design. The plug type is US/UK/AU/EU. The material of this product is PC+ABS. All condition of our product is 100% brand new. OEM and ODM are available in our company, and you deserve the best service. You can send more details of this product, so that we can offer best service to you!
90W Desktop Adapter,90W Desktop Power Supply,90W Desktop Power Cord , 90W Desktop Power Adapter
Shenzhen Waweis Technology Co., Ltd. , https://www.waweispowerasdapter.com